北京大学统计科学中心与数学科学学院博士生周航在姚方教授指导下,近期于《Biometrika》接收的研究成果首次给出了在函数型线性模型中,离散观测与采样频率对回归斜率函数(regression slope function)以及预测误差收敛速率的影响,并证明当采样率大于样本量的某一特定阶之后,根据离散噪音数据得到的斜率估计与利用完全观测函数得到的估计具有相同的收敛速率。该研究建立了函数型线性模型中“理想”假设和“现实”观测之间的联系,对函数型数据分析中的样本量和采样率的选取有重要的指导意义。

随着数据收集技术的快速发展,函数型数据在过去二十年中取得了广泛的发 展与应用。尽管传统函数型数据的理论分析通常假设能观测到整条函数,但在实际科学研究、生产生活中收集到数据往往是光滑函数在离散点上的采样。从完全观察到每条曲线这一“理想”假设到“现实”中只能观测到曲线的离散采样点之间存在着根本的差异。如何刻画离散观测以及测量误差对收敛速率的影响成为该领域一个重要的问题。直观上讲,随着采样点个数的增加,模型估计量的收敛速率会越来越快。当采样率超过样本量的某一特定阶时,利用离散观测的数据进行分析与利用全观测函数得到的收敛速率相同,这一阶叫做相变点(phase transition point)。尽管对于均值和协方差函数收敛性和相变点的研究已经较为全面,但在实际应用中有基础意义的函数型线性模型中,离散观测和采样误差如何影响回归函数的收敛速率仍是该领域悬而未决的开放性问题。与均值和协方差估计不同,线性模型中涉及到逆问题(inverse problem),而无穷秩的协方差紧算子又是不可逆的,如何在估计及分析中同时考虑光滑性(smoothness)和无穷维(infinite-dimensionality)这两个函数型数据的特质,成为这一问题区别于均值和协方差估计的难点。
现有函数型线性模型的理论分析基于发散个数特征函数估计的最优收敛速率。但在离散观测情形下,尚无法通过现有的理论技术得到这一最优收敛速率,从而无法得到线性模型中回归函数和预测误差的最优收敛速率。通过对扰动级数(perturbation series)中各项期望的详细计算,我们得到发散个数特征函数估计量收敛速率的期望上界,该结果相对于现有结果有着很大的提升,对各种基于离散观测的函数型数据模型的研究均有深刻的影响。基于这一结果,我们采用近似最小二乘估计结合样本分割策略来克服离散观测带来的理论困难。我们推导出回归函数估计量的理论性质并证明当采样率大于样本量的某一介于(1/2,1)之间的指数阶之后,根据离散数据得到的回归函数估计量与利用全观测函数得到的估计量具有相同的理论性质。这一结果与函数型数据均值与协方差函数估计的相变点1/4有着根本区别,体现了线性回归模型中逆问题导致的回归函数估计相变点的提高。从实用角度讲,在此相变点之上进一步增加个体函数上采样率不会提升最终所得估计量的精度(如图所示),这一结果对函数型数据回归模型中的样本量与相应采样率的选取有重要的实际指导意义。
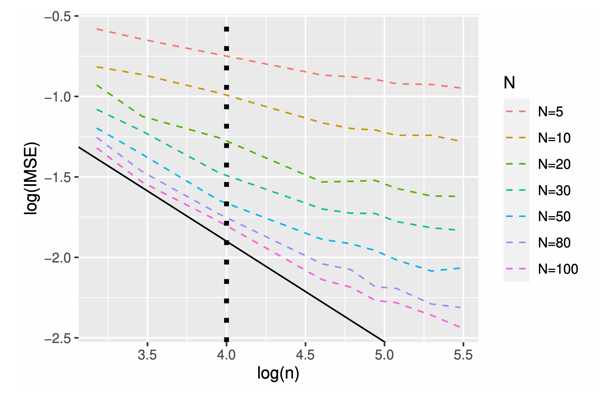
图:不同采样率(N)下回归函数的均方误差(IMSE)与样本量(n)的关系,黑色直线的斜率代表全观测情形下的斜率估计收敛的最优速率
《Biometrika》为国际统计学界影响最为广泛的顶尖学术期刊之一,周航为论文第一作者,2022年博士毕业后前往加州大学戴维斯分校进行博士后研究。通讯作者姚方为北京大学讲席教授,任北京大学统计科学中心主任、数学科学学院概率统计系主任,入选国家高层次人才计划。合作作者张慧铭也是姚方教授指导的博士生(2020年毕业),现在澳门大学从事博士后研究。
